If you're someone with domain expertise and a problem that's always bothered you: the barrier to building is gone. The question isn't whether you have the technical skills. The question is whether you're willing to make a start.
3 months, 6 data sources, and a live analytics platform, all without an engineering team.
The Numbers
| Metric | Nov 30, 2025 | Jan 31, 2026 | Growth |
|---|---|---|---|
| Lines of Python | 10,402 | 28,430 | +173% |
| Data Sources | 2 | 6 | +4 |
| Tracked Employers | 11 | 847 | +77x |
| Raw Jobs | 1,689 | 40,265 | +24x |
| Job Subfamilies | 13 | 17 | +4 |
| Locations | 3 | 5 | +2 |
Cumulative Job Records
Growth from initial scrape to 40K+ jobs tracked
Why This Problem
I spent several years in HR tech at eFinancialCareers and DHI Group watching both sides of the hiring marketplace struggle with the same issue: Nobody actually knows what the market looks like and how this is going to affect their ability to recruit or be recruited.
Candidates guess at who might be hiring for their unique combination of experience. Recruiters are unclear about who they're competing with for talent. Hiring managers are asking for skills that are in short supply. Everyone operates on incomplete information because comprehensive, current market data doesn't exist in an accessible form. All the while, AI continues to disrupt and complicate the hiring process.
When I found myself job hunting after a layoff in 2024, I felt this problem personally. What are companies actually hiring for? What skills keep appearing? Is this a Product or Project role? How technical do I need to be? What happened to the remote work dream??? A quick skim through LinkedIn, Glassdoor and HR subreddits lays bare the stresses and strains of a much flatter and AI-disrupted hiring landscape. What if I could in some small way, help candidates to identify gaps in their skillset or signpost them to employers that might be a good fit?
On a personal level, I also wanted a portfolio project that proved I could build an e2e data pipeline with AI, not just manage teams that build. The perfect confluence of good for the market and good for me.
So I set out to build a job market intelligence platform: scrape postings from multiple sources, classify them with LLMs, track trends over time, and surface insights.
Product Discipline, Not Vibe Coding
Most AI-assisted projects fail because they start coding immediately. I took a different approach, a product approach.
Before writing a line of code, I created:
- A product brief defining success metrics and constraints
- 35 marketplace questions the platform needed to answer if we could deem it a success
- A taxonomy schema for how jobs should be classified (function, level, skills, sector), based on my years of experience within the sector.
- Epics and stories structured the same way I'd run any product
Example marketplace questions:
| Audience | Question |
|---|---|
| Candidate | Is demand for my skill increasing or decreasing compared with last year? |
| Employer | Which job subfamilies are growing fastest in Product/Data in each city? |
| Candidate | When are most jobs in my field posted (day/month patterns)? |
All of this documentation lived in the repository, accessible to the agent. When I asked it to build a job aggregator or fix a bug, it had context, not just on the immediate task, but on why that task mattered and how it mapped into the larger system. This meant we could iterate instead of building randomly. It was executing against a product plan that evolved as we learned.
What Got Built
Three products across an expanding set of markets and job types:
Interactive real-time analytics on role demand, skills trends, seniority distribution, and working arrangements across major tech hubs.
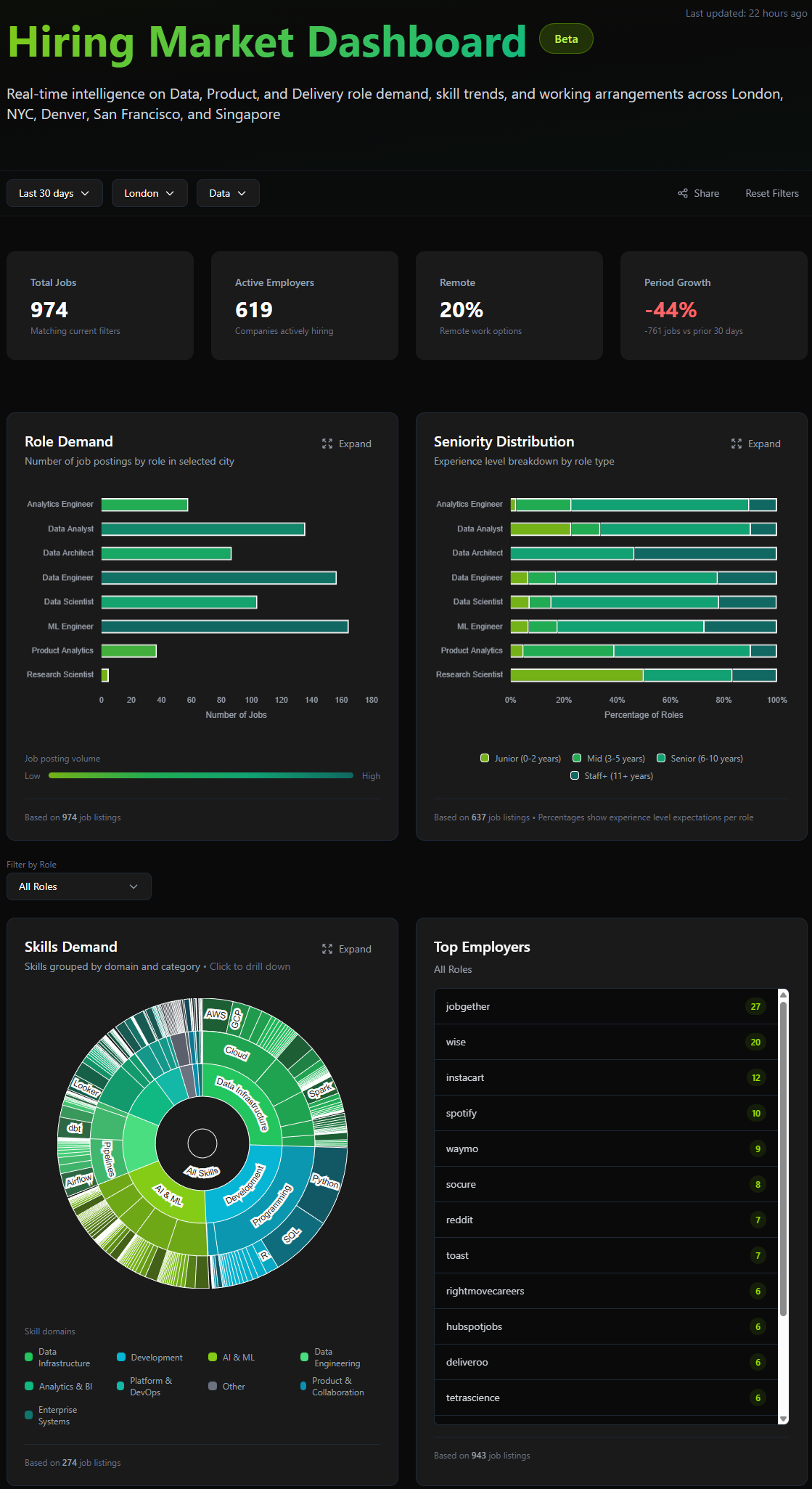
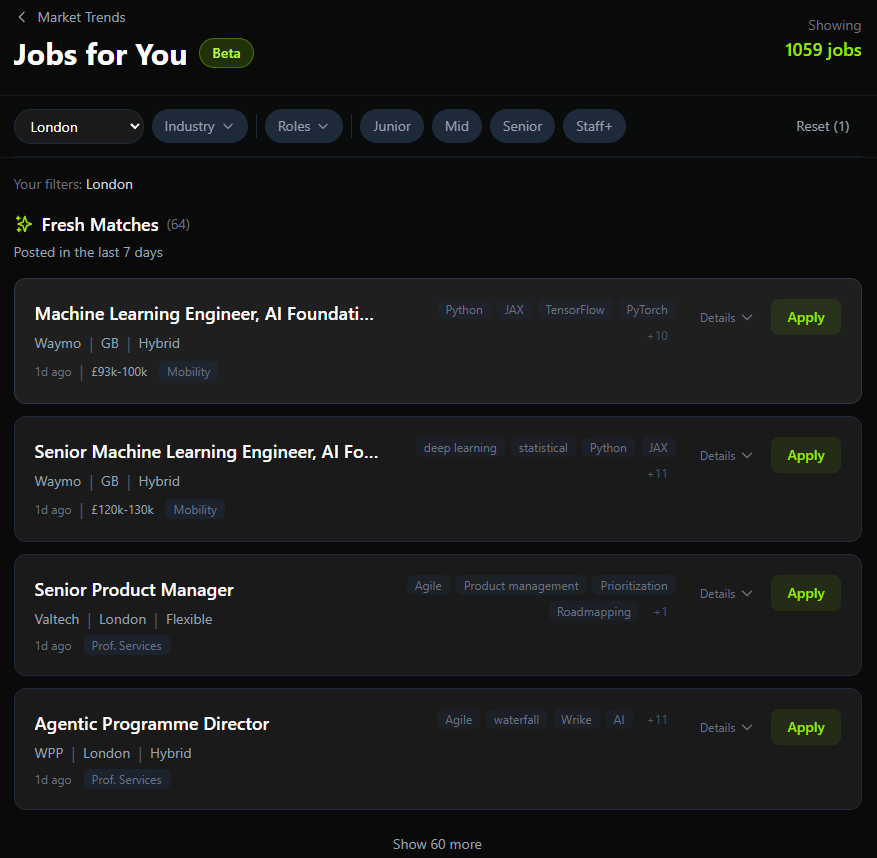
Curated job listings organised by freshness, employer activity, compensation, and remote options. Direct employer postings only, no aggregators or recruiters.
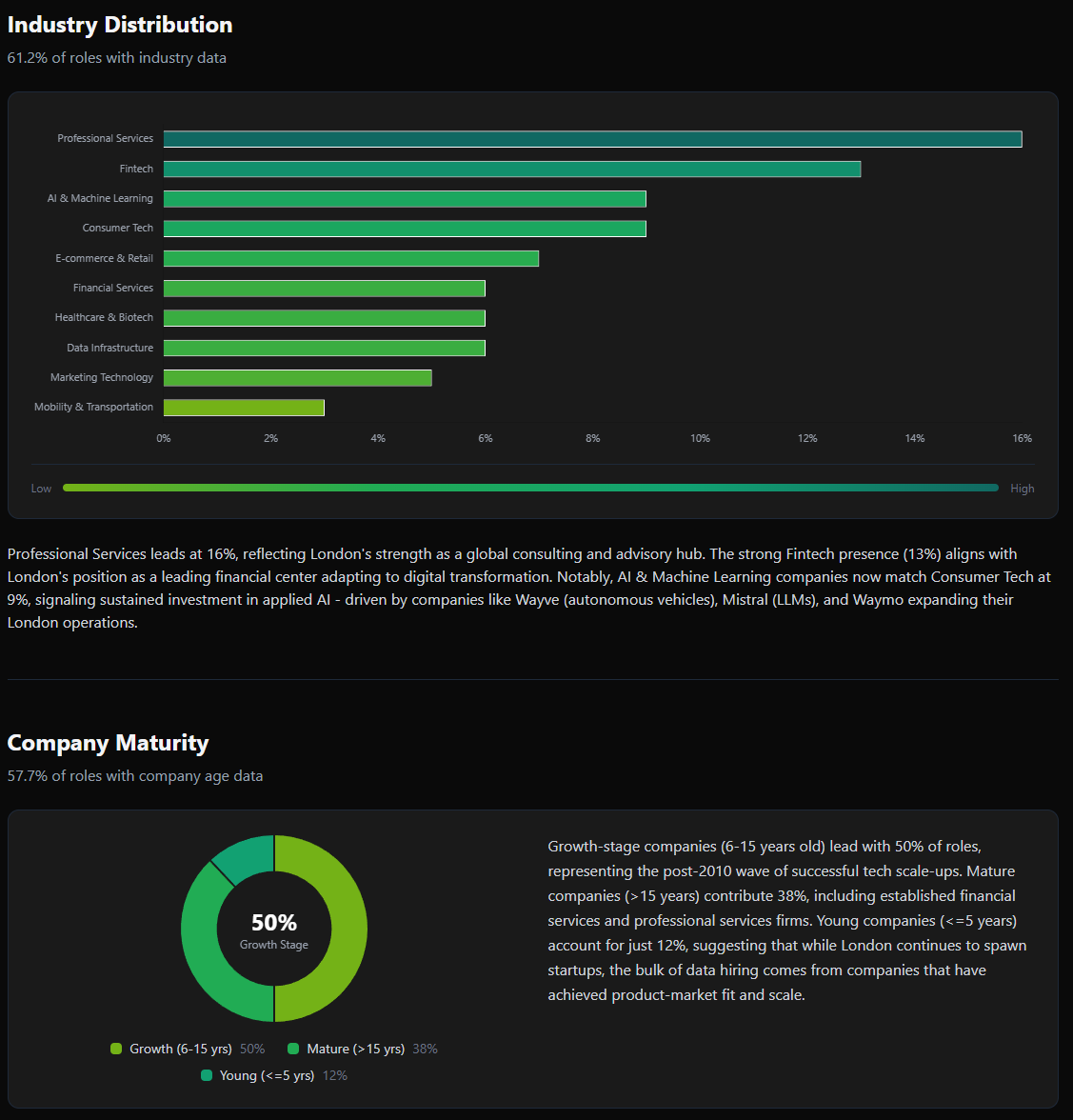
In-depth analysis of hiring trends by city: industry distribution, company profiles, compensation benchmarks, and skills demand.

The original vision was deliberately simple: pull jobs from Adzuna's API, classify them with Claude, store the structured results and a raw copy of the job. A weekend project, maybe two.
Once I got into the weeds it became clear that the role Adzuna would play was limited owing to their API limitations. I needed to look at other sources for cleaner data and a more robust pipeline for integration.
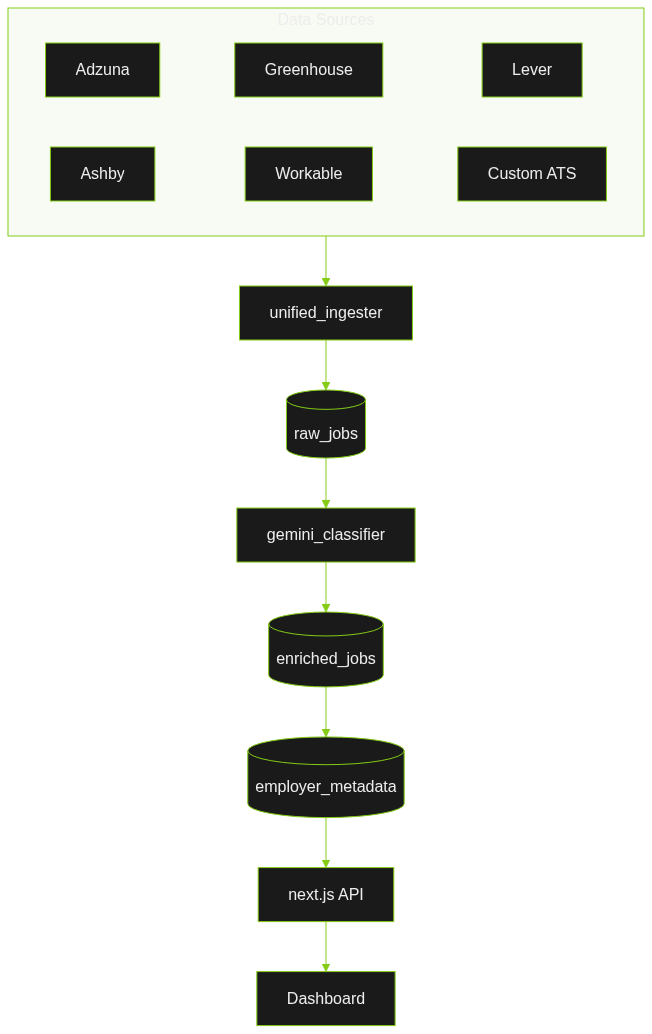
Six data sources instead of one. An employer intelligence layer with industry classification, company size, and headquarters data. Seven GitHub Actions workflows running automated scrapes on schedules. A classification system using Gemini 2.5 Flash with fallback to Claude Haiku.
The scope grew, but it grew in response to real problems discovered during development, not feature creep.
The Pivots That Mattered
Pivot 1: Adzuna's Text Truncation
Two weeks in, I discovered Adzuna's API returns truncated job descriptions. Doh! 100-200 characters instead of full postings. Skills extraction F1 score: 0.29. Unusable.
Solution: We were going to need to go after jobs at source. Greenhouse was by far the largest ATS platform when looking at tech. So we built a Greenhouse aggregator using Playwright browser automation to capture full job descriptions (9,000-15,000 characters). F1 score jumped to 0.85+. Eureka, high quality, mineable data!
The lesson: data source quality determines your ceiling. No amount of prompt engineering fixes garbage input.
Pivot 2: Claude to Gemini
Started with Claude Haiku for classification at $0.00388 per job. Gemini 2.5 Flash does comparable work for roughly $0.0005 per job - 88% cheaper. There's a reason Google is the behemoth it is today, 2.5 Flash is an absolute workhorse and the unit economics were simply too good not to invest in switching.
At 20,000+ jobs, that cost difference matters. And in the case of failure, we built a classifier router supporting multiple LLM backends with automatic fallback.
Pivot 3: Manual to Automated
By late December, I was running scrapers manually. This was OK. I am a gamer, my gpu has been going UP in price the longer I've had it thanks to Nvidia. But jobs were starting to run long, Playwright is notoriously compute heavy. I had to get orchestration into the cloud. Github, with its generous allowances for open source meant I could build all seven GitHub Actions workflows scheduling jobs to run at different points in time across the week. Finally, the system was running itself.
Pivot 4: Moving from batched to incremental upserts
A couple of long running jobs where classification failed highlighted that I needed to move from batching to incremental upserts to avoid losing job data mid-pipeline. This was the gritty reality of moving from a vibe-coded extract - classify - insert to extract - load - classify - transform.
Where Agents Excel (and Where They Need Guardrails)
The split: 90% agent, 10% me.
My 10% was: checking code output, running tests and utilities, overall direction on architecture, pipeline design, testing strategy, and analytics presentation.
The agent's 90% was: writing the actual code, implementing patterns, creating tests, updating documentation.
Where agents excel:
- Scaffolding and boilerplate - spinning up scrapers, API integrations, and test structures happened within minutes. And in some cases (Ashby and Lever for example), they were very successful with minimal effort.
- Pattern replication - once you establish a pattern, they apply it consistently. claude.md was a great source for this, enabling us to set expectations around how we should approach the build.
- Tracing dependencies - as the project became more complex, tracing core data processing modules, their sequence in the pipeline and dependencies became more important for me to understand.
Where agents need guardrails:
I built many "Skills" specialised instruction sets the agent references for different tasks:
| Skill | Purpose |
|---|---|
| company-curator | Manage the scraped company universe, validate career pages |
| config-validator | Validate YAML/JSON configs, maintain blocklists |
| qa-tester | Review coverage, write tests, identify regressions |
| repo-reviewer | Audit for duplication, enforce DRY principles |
| security-audit | Test entry points, scan for credential exposure |
| system-architect | Plan features, evaluate abstraction opportunities |
Without these, agents drift. CLAUDE.md had ballooned to 64KB before I cut it to 5.8KB, a 91% reduction. The agent was suggesting increasingly complex solutions because it had too much context, not too little.
Where I had to intervene:
- LLM vs. deterministic decisions - agents will use LLMs for everything. But filtering out low-quality job sources? That's a YAML config and Python, not an API call. I built a three-tier pre-filter (title keywords, location matching, agency blocklist) that eliminates 94.7% of jobs before they hit the classifier which was a huge cost saving. Use LLMs for genuinely stochastic problems like classifying whether a role leans to IC or management.
- Commit hygiene - agents occasionally ignore .gitignore. I caught credentials heading toward commits more than once.
- Over-engineering - left unchecked, agents build elegant solutions to problems you don't have. Constant pressure on YAGNI (You Aren't Gonna Need It) was required.
The Cost Reality
What I actually spent:
| Period | Monthly Cost | Notes |
|---|---|---|
| November | £20 | Claude Pro subscription |
| December | £20 + £36 overages | Frequently hitting Claude session limits during intensive work which was enraging! |
| January | £30 | Claude Max (£90 shared across several projects) |
Effective cost for this project build: roughly £30/month.
No orchestration costs (GitHub Actions free tier). No cloud costs (Supabase free tier, Google Cloud's £250 free credit covered Gemini API usage). One-time domain fee with Vercel.
If I keep the product at its current scope without growth, I expect ongoing costs around £25/month for compute when I eventually move off free tiers.
The "you can start for £20" claim is real but with caveats. Intensive AI-assisted development hits subscription limits, FAST. Budget for upgrades if you're building seriously. Opus is the gold standard at the moment for coding, but other (cheaper) LLM options are available.
What This Proves
If the reader takes one learning from this, let it be:
Software engineering, at least for smaller products, is now commoditised.
You no longer need a team of technical experts to build a robust data-intensive product. A £20 subscription and the will to get started is enough.
I don't think that this is the end of software engineers, quite the opposite. Software engineers using AI will become some of the most important people in business, the new term being coined is the Product Builder. PMs, designers, analysts, domain experts: if you can define a problem clearly and think systematically about solutions, you can ship software.
I'm a PM with a data and analytics background. I can read code well enough to understand the high level, but I'm by no means an expert. I couldn't write a production system from scratch. But I can:
- Define problems clearly
- Structure work into manageable pieces
- Make architecture decisions (when to use LLMs vs. deterministic code)
- Recognise when solutions are over-engineered
- Test ruthlessly
- Know when to intervene vs. let the agent run
These are product skills. They transfer directly to AI-assisted development.
The secondary benefit: building this made me a better PM. I'm starting to more deeply understand the trade-offs and ambiguity engineers navigate daily. The uncertainty of debugging. The temptation to over-engineer. The tension between "do it right" and "ship it". And the constant scope pivots as we learn more about the problem we're trying to solve.
That empathy will make me more effective in every engineering collaboration going forward.
The Opportunity
For years, I've carried problems I wanted to solve but couldn't resource. The hiring market information asymmetry I experienced at eFinancialCareers. Internal tools that would've saved teams hours. Analytics products that never made the roadmap.
Now those problems are within reach.
If you're someone with domain expertise and a problem that's always bothered you: the barrier to building is gone. The question isn't whether you have the technical skills. The question is whether you're willing to make a start.